Skip to main content
CERN
Accelerating science
Sign in
Directory
Main navigation
Toggle navigation
Resources
Data Management Plans
News
OS Report
Policies
Services
b
Open Source Programme Office
CAP
CDS
CERN Open Data Portal
INSPIRE
SCOAP3
Zenodo
Open Science Activities
Open Access
Open Data
b
Open Data for Education
Open Source Software
Open Source Hardware
Research Integrity
Open Infrastructure
Research Assessment
Training & Outreach
Citizen Science
About
Mission
Governance
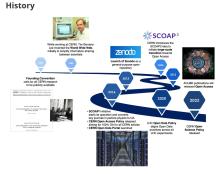
History
Contact us
OS Office
SEARCH
Enter the terms you wish to search for.
News
News
SCOAP3 successfully concludes second evaluation period of Open Science Elements
2026-06-19
CERN leads project to make EU scientific data more accessible with AI
2026-06-12
CERN joins European project to professionalise data stewardship
2026-06-11
CERN’s KiCad component library now open source
2026-05-07
Open data, in practice: the first ATLAS Open Data tutorial at IdeaSquare
2026-04-22
CERN to host Europe’s flagship open-access publishing platform
2026-03-26
2026 SCOAP3 Books Program Open for Submissions
2026-03-12
LHCb releases service to access Run II data
2026-03-04
Help shape the future of research data management at CERN and in Switzerland
2025-11-10
CERN publishes its first Open Science Report
2025-09-15
5th SCOAP3 Forum held on June 18th 2025
2025-07-11
CERN’s Open Source Programme Office Publishes First Report
2025-06-16
CERN joins the build-up phase of EOSC Federation
2025-04-24
SCOAP3 publishes first results of the new open science mechanism
2025-04-02
Open Science Fair 2025: Call for Contributions
2025-04-02
INSPIRE releases New Dataset Discovery Feature
2025-03-05
Strengthening open infrastructures for scholarly books
2025-01-29
Blog post: CERN a Top Data Contributor to ORCID through INSPIRE’s Integration for High-Energy Physics Community
2024-12-06
CERN70: Continuing CERN’s legacy of open science
2024-11-28
SCOAP3 is celebrating a decade of open access
2024-08-27
Authors: make sure you choose the right license when you publish an article
2024-08-13
CMS Open Data workshop & Hackathon 2024
2024-08-05
How can I use CERN’s Open Science Office?
2024-07-15
ATLAS releases 65 TB of open data for research
2024-07-04
CERN: An extraordinary human endeavour
2024-06-09
Northwestern and CERN Step into Collaborative Leadership Role, Fostering Innovation in Open Science
2024-04-26
CMS releases Higgs boson discovery data to the public
2024-04-18
CMS releases 13 TeV proton collision data from 2016
2024-04-08
Enabling open access to books
2024-03-06
LHCb experiment releases all of its Run 1 proton–proton data
2024-01-17
UNESCO Open Science Outlook launched at CERN
2023-12-14
CERN’s new Open Source Program Office
2023-11-22
CERN/NASA Open Science Summit 2023: Closing Statement issued
2023-11-01
CERN-NASA Open Science Summit 2023
2023-07-14
Celebrating the 10th anniversary of Zenodo!
2023-05-08
OS Policy: Implementation Plan released
2023-04-13
ICRC & CERN: open source technologies for humanitarian action
2023-03-24
CERN supports open access publishing for books
2022-12-22
LHCb releases first set of data to the public
2022-12-08
CMS completes release of Run-1 proton-proton data
2022-12-05
CERN publishes Open Science Policy
2022-10-01
SCOAP3 reaches 50’000 articles milestone
2022-05-19
First CMS Open Data from LHC Run 2 released
2021-12-20
Zenodo: Hardening our service
2021-12-07
CERN announces new open data policy
2020-12-11
ATLAS releases 13-TeV open data for science education
2020-02-13
more